Why Your AI Enterprise Search Fails—and How to Fix It
By Ted Leis
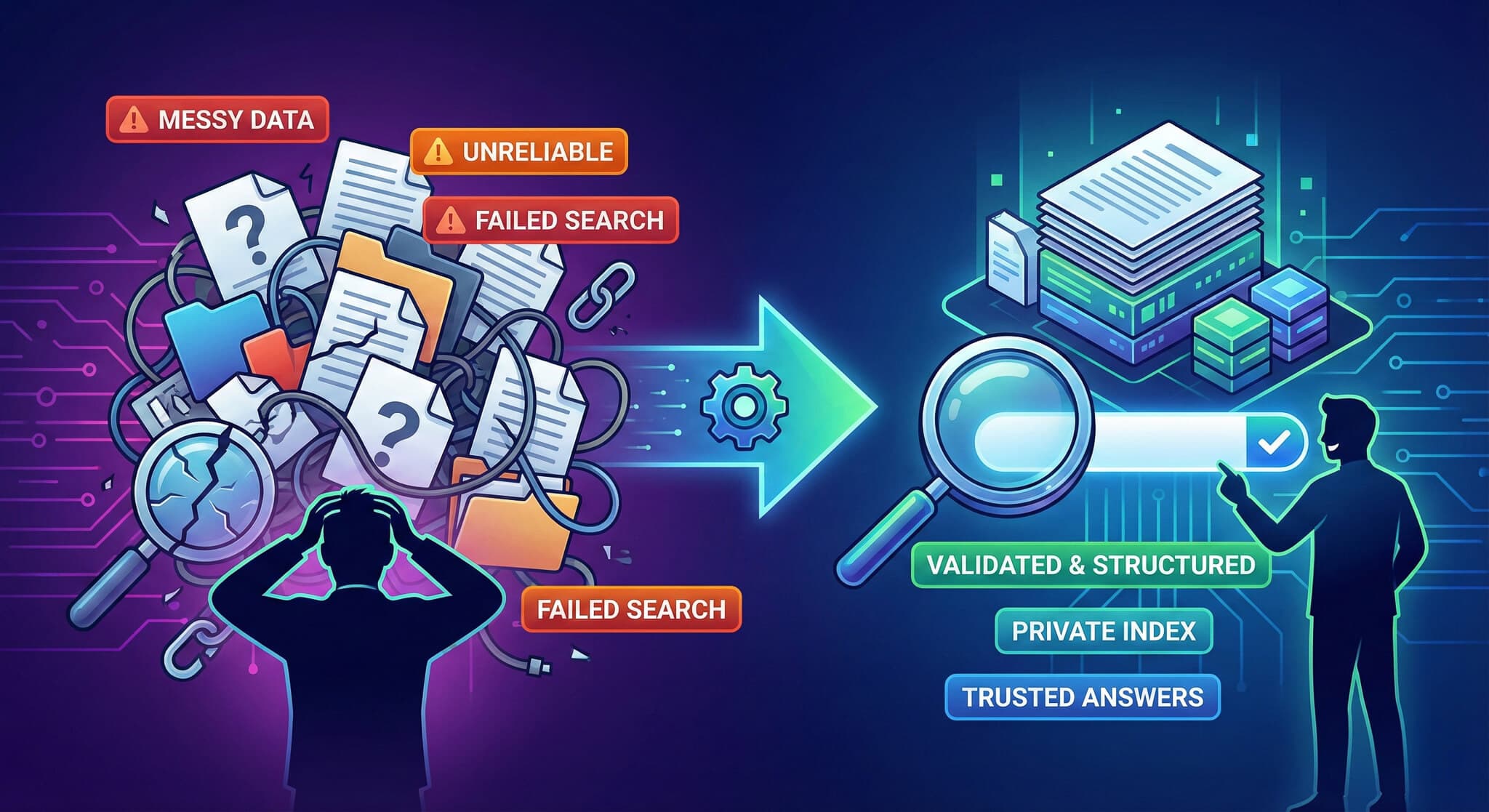
Imagine you’re an IT director or an executive leading your company’s AI strategy. Every new AI tool promises to unlock all your company’s knowledge—seamlessly, effortlessly. But too often, these promising pilots stumble. They run into the same wall: the data is messy, the search is generic, and the results are unreliable.
The problem isn't the AI. It's the foundation it’s built on.
The Prototype Trap: Why It Looks Easy Until It Isn’t
It’s tempting to think that success with a small internal prototype means you’re ready for enterprise scale. Modern tooling makes it fast to stand up a search demo. But scaling that prototype into something production-ready—and reliable across departments, data types, and access controls—is where most teams run into trouble.
The value of AI search becomes obvious the moment it works—when someone asks a hard question and gets the right answer, fast. But getting to that point requires much more than connecting a search model to your files. It requires a foundation that preserves structure, meaning, and governance across every source.
Step One: Process Like Your Project Depends on It (Because It Does)
Everything hinges on the first step: processing and validating the data.
The problem
Most teams trust converted content without proof. When conversion quality isn’t measured and documented, bad text and broken structure slip in, and the foundation becomes unstable—no amount of tuning fixes it. By the time that data is indexed, the issues are amplified and expensive to unwind.
How we solve it
We don’t ask you to re-check our work; we’ve built validation into the pipeline. Each document is processed and structured, then checked for completeness and fidelity to the source, with access controls applied at ingest. Titles, sections, captions, and tables are extracted and enriched with metadata; content is labeled and versioned; and the result is clean, trustworthy input for everything that follows.
Step Two: Prepare the Data the Right Way
The problem
After processing, the next stage is just as critical. When teams treat every file the same and skip quality checks, formatting drifts across sources, acronyms lose meaning, units and dates don’t line up, and code or tables break. The search system is then forced to reason over mixed signals, which drags down relevance and makes answers feel off.
How we solve it
Before any model touches your content, we make it consistent and adapted to each content type. Each document type gets the treatment it needs—technical manuals, HR policies, and legal contracts are handled differently. We prepare the format and structure, spell out acronyms and tie them to their meanings, keep technical notation intact, align units and dates, and apply domain-aware rules so terms mean what your teams expect.
Think of it like organizing a messy warehouse: when everything is in the right bin, clearly labeled, and arranged the way people actually use it, the system can find exactly what you need. If it’s just a pile of stuff—it won’t.
Step Three: Search That Understands Your Business
The problem
Many teams wire a “smart search box” to their files and expect great results. Without building permissions and trust signals into the index from day one, sensitive content can leak or needed content gets hidden. Old drafts compete with current versions. Duplicates pile up. The same word means different things in different departments, so results look relevant but miss the mark. And when answers don’t point to the exact paragraph and version, people can’t verify them quickly—trust fades.
How we solve it
We build a private index that mirrors how your business actually works—and we instrument it with evidence. Each passage carries its owner, version, source, date, and who can see it, so access is enforced from the start and honored all the way to the answer. Results are ordered by what matters to you—authority, freshness, and trusted owners—not by what’s popular on the web. Every answer is grounded in specific passages with clear trace-back, and everything stays inside your company’s network and cloud accounts—under your control. It’s your data only, organized and ranked by your rules.
Our engine is built exclusively on your domain knowledge, tuned to your vocabulary, and governed by your access controls. What it retrieves is entirely your own. Pinpoint accuracy, with rich semantic context, summary of the results, and references to the original data. And one of the other great benefits of this grounded system is that it eliminates guesswork and prevents hallucinations. This isn’t ChatGPT sprinkled on top of SharePoint, and there’s no pull from the public web. It’s your data only, organized and ranked by your rules.
From Failed Pilots to Production Success
When the foundation is right, search starts to feel simple and useful. People get the current policy, not last year’s draft. Each answer shows the exact paragraph it came from, with the owner and version, so decisions are defensible. Access boundaries hold from login to answer, which keeps security and compliance comfortable. Because the system understands your vocabulary, people can ask questions in their own words and still land on the right source.
The operational impact is immediate. Fewer “where is this?” messages. Less dependency on subject-matter experts for routine questions. Faster onboarding for new hires. Teams move from browsing to answering, and trust in the system grows because it proves itself in daily use.
The Takeaway
If your AI search project is stumbling, the issue is almost never the model. It’s the data foundation and the way it was built. Tensor Data Dynamics does the hard parts end-to-end: we process and validate your content, prepare it so meaning and structure are preserved, and build a private index that ranks results by what matters in your organization while enforcing access all the way through to the answer. Nothing leaves your company’s network and what the system retrieves is entirely your own.
Choose this approach if you want a system people rely on, not a demo. It shortens the path from prototype to production, reduces risk by keeping data governed at the source, and pays back every day in faster decisions and fewer blind spots. We build from the ground up so your teams don’t just search—they find.